Technologies / Voice Enhancement
 |
 |
 |
||
| Eliminates echo in voice communication devices. | Alleviates acoustic coupling between microphone and speakers. |
Uses two microphones to create a directional or noise-canceling microphone to adaptively preserve the transmitted voice signal.
|
||
 |
 |
 |
||
|
Detects wind noise and removes it using sub-band processing.
|
Digitally increases signal gain (amplification) when the voice signal is weak and conversely compresses the voice signal when it is strong.
|
Continuously and automatically adjusts sound based on ambient noise level and spectrum.
|
||
 |
 |
 |
||
|
Detects and attenuates reverberant speech within an audio signal while preserving the direct speech to make it more intelligible using classical signal processing techniques.
|
Detects and attenuates reverberant speech within an audio signal while preserving the direct speech to make it more intelligible using neural network signal processing techniques. |
Increases the intelligibility of speech by slowing it down dynamically in real time by up to 40% - useful for better comprehension of “fast talkers”, foreign languages, and recorded messages.
|
||
 |
 |
 |
||
| EasyWatch™
Dynamically slows down speech segments in TV sound, making fast speech easier to understand. Video is slowed in parallel, ensuring synchronization of audio and video streams.
|
Adjusts the dynamic range of an audio signal based on a predefined rule, enhancing soft sounds while maintaining loud ones.
|
Enhances single-channel speech signals by increasing the signal-to-noise ratio, improving speech intelligibility, and reducing listening fatigue using traditional audio processing techniques.
|
||
 |
 |
 |
||
|
Enhances single-channel speech signals by increasing the signal-to-noise ratio, improving speech intelligibility, and reducing listening fatigue using neural network processing techniques.
|
Advanced sound pick-up voice enhancement technology for earbuds (TWS) that utilizes the combination of an internal (in-ear) bone conduction sensor and external Adaptive Directional Beamforming microphones to robustly discriminate between voice and noise. |
Advanced sound pick-up voice enhancement technology for earbuds (TWS) that utilizes the combination of an internal (in-ear) microphone and external Adaptive Directional Beamforming microphones to robustly discriminate between voice and noise.
|
||
 |
 |
 |
||
|
Masks the effects of digital voice signal packet loss by reconstructing a synthetic signal to cover missing data.
|
Detects human speech in an acoustic signal and allows for low-power, always-on voice detection in various devices.
|
For headphones using four microphone signals (2 on each earcup) to create a voice capture zone, ensuring clear voice transmission even in noisy or windy environments.
|
||
 |
 |
|||
|
Improves speech intelligibility in movies through de-emphasis of overbearing background sounds and music.
|
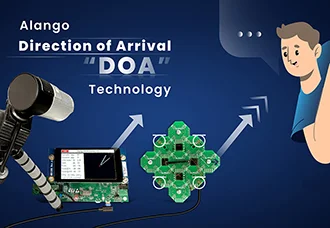
Reliably determines the direction of human speech in an acoustic signal in real time.
|